; padding: 0px; max-width: 100%; box-sizing: border-box !important; word-wrap: break-word !important;"/>
Andreas Muller:一般来说,与 Scikit-learn 和机器学习相关的常见错误有两种。
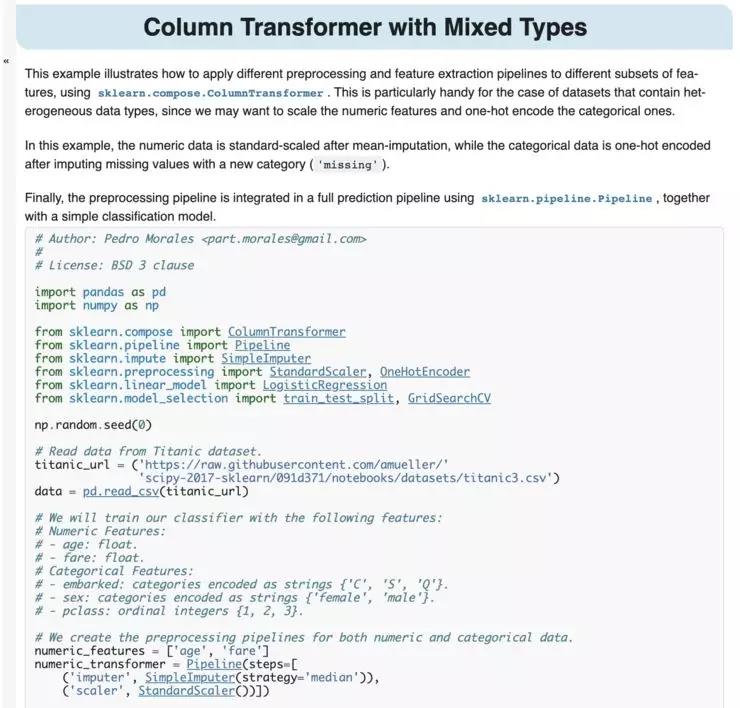
1.对于 Scikit 学习,每个人都可能在使用管道。如果你不使用管道,那你可能有些地方做错了。2 年前,我们引入了列转换器,它允许你处理具有连续和分类变量的数据,或者处理其他类型 One-Hot 编码器时,一切都很好。
2。我在机器学习中看到的一个常见错误是没有对度量标准给予足够的关注。Scikit-learn 将精度用作默认度量。但一旦你有了一个不平衡的数据,准确度是一个可怕的指标。你真的应该考虑使用其他指标。我们不会改变默认的度量标准,因为准确性被广泛使用,而且有如此清楚的解释。但是,在机器学习中,查看其他度量并为你的用例考虑是否使用它们是最常见的问题。
什么是管道?如果它不准确,还有什么其他指标更适合机器学习?
在 Scikit-learn 中,每个 ML 模型都封装在一个称为「估计器」的简单 python 类中。通常在机器学习过程中,你可能会有一个带有一系列预处理步骤的分类器。管道允许你封装所有预处理步骤、特征选择、缩放、变量编码等,以及通常在单个估计器中具有的最终监督模型。
所以你有一个对象来完成你所有的工作。它非常方便,能够使编写错误的代码出现的更少,因为它可以确保你正的训练集和测试集是一致的。最后,你应该使用交叉验证或网格搜索 CV。在这种情况下,重要的是所有的预处理都在交叉验证循环中进行。如果在交叉验证循环之外进行功能选择,可能会发生非常糟糕的事情。但在你的管道中,你知道一切都在交叉验证循环中。

Andreas Muller 哥伦比亚系列讲座
对于度量,它们通常在二进制分类中被忽略。在二进制分类中,精度取决于你的目标是什么。我喜欢看 ROC 曲线下的面积和平均精度。这些是某种细粒度的度量。我也喜欢看精确召回曲线(AUPRC)。这些指标的意义在于,它们不依赖于你应用的决策阈值,因为它们是排名指标。所以你需要决定在哪里设置阈值来表示「在什么概率下我说是 1 类还是 0 类?」。
你可以研究的其他指标是 F1 指标或平均召回率/精确度,这些也很有趣。
Haebichan Jung:Scikit-learn 包中是否有其他工具或功能让你觉得使用不足或被低估?
Andreas Muller:




 个人主页
个人主页









